
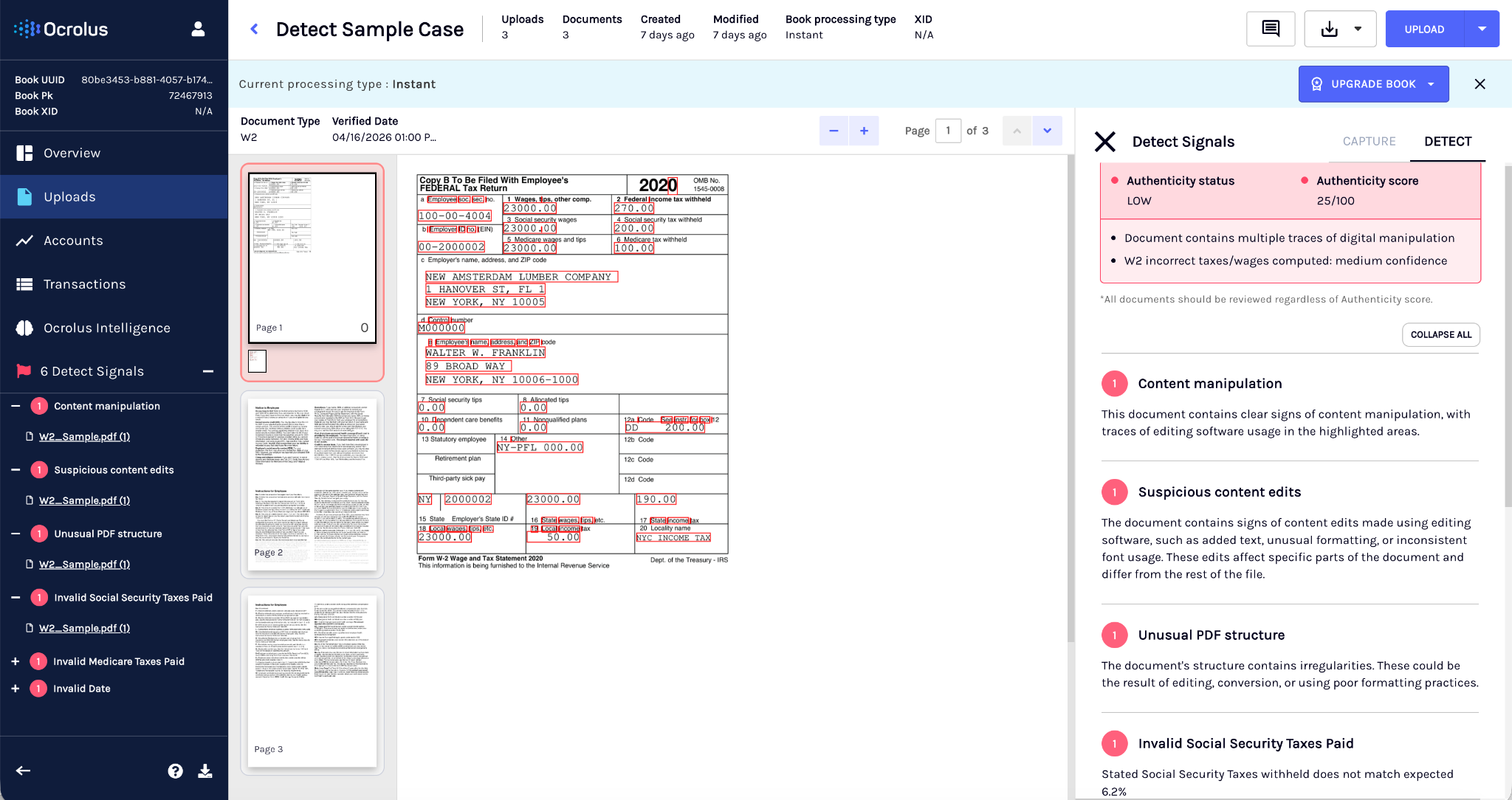
Authenticity Status
Authenticity Status provides a simple and tiered outcome for document integrity. The Authenticity Status calculation method is same as Authenticity Score (0-100) but its derived on signals and reason codes. It helps operational teams quickly assess document risk while preserving detailed scoring for automation and policy workflows.
A classification layer that derives a categorical result from the Authenticity Score and underlying detection signals, mapping documents to one of three statuses (High, Medium, Low). This helps operational teams quickly determine how a document should be handled.
| Status | Meaning | Suggested action |
|---|---|---|
| High | Document appears authentic | Continue standard processing |
| Medium | Some anomalies detected | Manual review recommended |
| Low | Strong indicators of fraud | Flag for investigation |
Authenticity Status modes
Authenticity Status categorizes a document based on its integrity signals and Authenticity Score. This classification helps operational teams quickly determine how a document should be handled in a workflow. Detect supports the following two Authenticity Status modes. You can get the Detect configured to return binary or ternary Authenticity Status depending on your workflow requirements.
- Ternary mode (default): This is a default which provides three possible outcomes, High (Pass), Medium (Review), and Low (Fail). High indicates low integrity risk and documents can proceed or be automatically approved. Medium indicates moderate risk and the document should be reviewed manually. Low indicates high risk and the document should be escalated or rejected.
- Binary mode: This provides two outcomes: High (Pass) and Low (Fail). High indicates the document meets authenticity checks and can proceed in the workflow. Low indicates integrity concerns and the document should be rejected or escalated. Medium scores are automatically mapped to either High or Low based on defined thresholds, removing the need for a manual review tier.
NoteAuthenticity Status configuration (binary or ternary) is managed by Ocrolus and is not self-service. To make this configuration, our support team at [email protected] or raise a support request.
Users of Authenticity Status
Authenticity Status supports teams responsible for fraud detection, risk management, compliance, and operational review. It is commonly used by fraud analysts, underwriters, processing teams, review operations, and QA teams during document review, audits, and post-close verification workflows.
Authenticity Score vs. Authenticity Status
| Feature | Authenticity Score | Authenticity Status |
|---|---|---|
| Output type | Numeric value (0–100) | Categorical result |
| Purpose | Provides detailed integrity scoring | Provides a clear decision outcome |
| Calculation method | Based on content analysis, document structure analysis, and manipulation detection signals | Derived from the Authenticity Score and integrity signals |
| Interpretation | Lower scores indicate higher risk of manipulation | Categories represent document risk levels |
| Typical use | Automated decision rules, threshold-based workflows, and risk scoring models | Operational routing and manual review workflows |
Viewing Authenticity Status results
The Authenticity Status results are available in both the Ocrolus Dashboard and API responses. To learn more see, Visualization section.
Updated 2 months ago